For roughly the last year I have been working on bringing secure scuttlebutt to the browser. The result of this is ssb-browser-core.
Secure scuttlebutt allows one to write an unforgeable append-only log of messages and to exchange these messages between nodes in a p2p network without a central authority. With this, one can build event sourcing systems.
The first secure scuttlebutt implementation (there are also Go and rust implementations now) is a normal node application and thus requires a lot of things that are not readily available in a browser such as a filesystem and crypto. Filesystem api is provides by random-access-web that for chrome uses the file system api which is quite fast. Crypto is provided by libsodium.js which uses wasm and is roughly 90% the speed of running it natively. The last part is network, he we rely on web sockets which gives us a long running connection to a server somewhere. With epidemic broadcast trees to exchange messages, one can get the latest messages for several hundred feeds (probably also thousands) in a reliable and low latency manor.
With this, one is able to run secure scuttlebutt in any environment where the browser works. This includes Chrome, Firefox, Safari and on android and iOS. By running as a progressive web app it is possible to side step the normal walled garden of the dominant mobile operating systems. Jacob also managed to get it running as a web extension.
The main application for showing what can be built on top of these primitives is a social network called scuttlebutt. In order to test the functionality of the core, I wrote a demo application with most of the basic functionality for having conversations. Other applications that has been built on top of the protocol includes gatherings, chess, git, books.
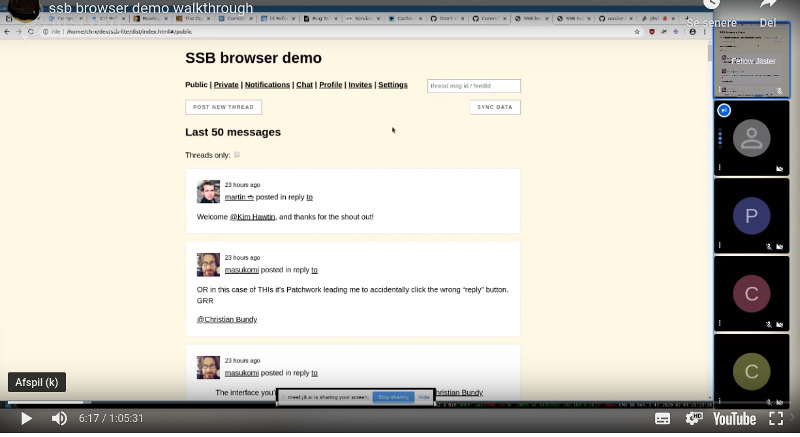
I did a walkthrough of how it works for a few people in the SSB community. You can watch the video below.
This weekend I’ll be at the University in Basel to discuss SSB and related p2p technologies.